|
I am a researcher working on cutting-edge research projects at the intersection of Computer Vision, Computational Photography, and Machine Learning at the Computational Photography team of Meta Reality Labs. My research interests cover 3D vision, neural rendering, low-level vision, and visual-linguistic understanding. |
|
|
|

|
We present a simple but effective technique to boost the rendering quality, which can be easily integrated with most volumetric view synthesis methods.
The core idea is to transfer color residuals (the difference between the input images and their reconstruction) from training views to novel views.
|

|
We present an algorithm for estimating consistent dense depth maps and camera poses from a monocular video.
|
|
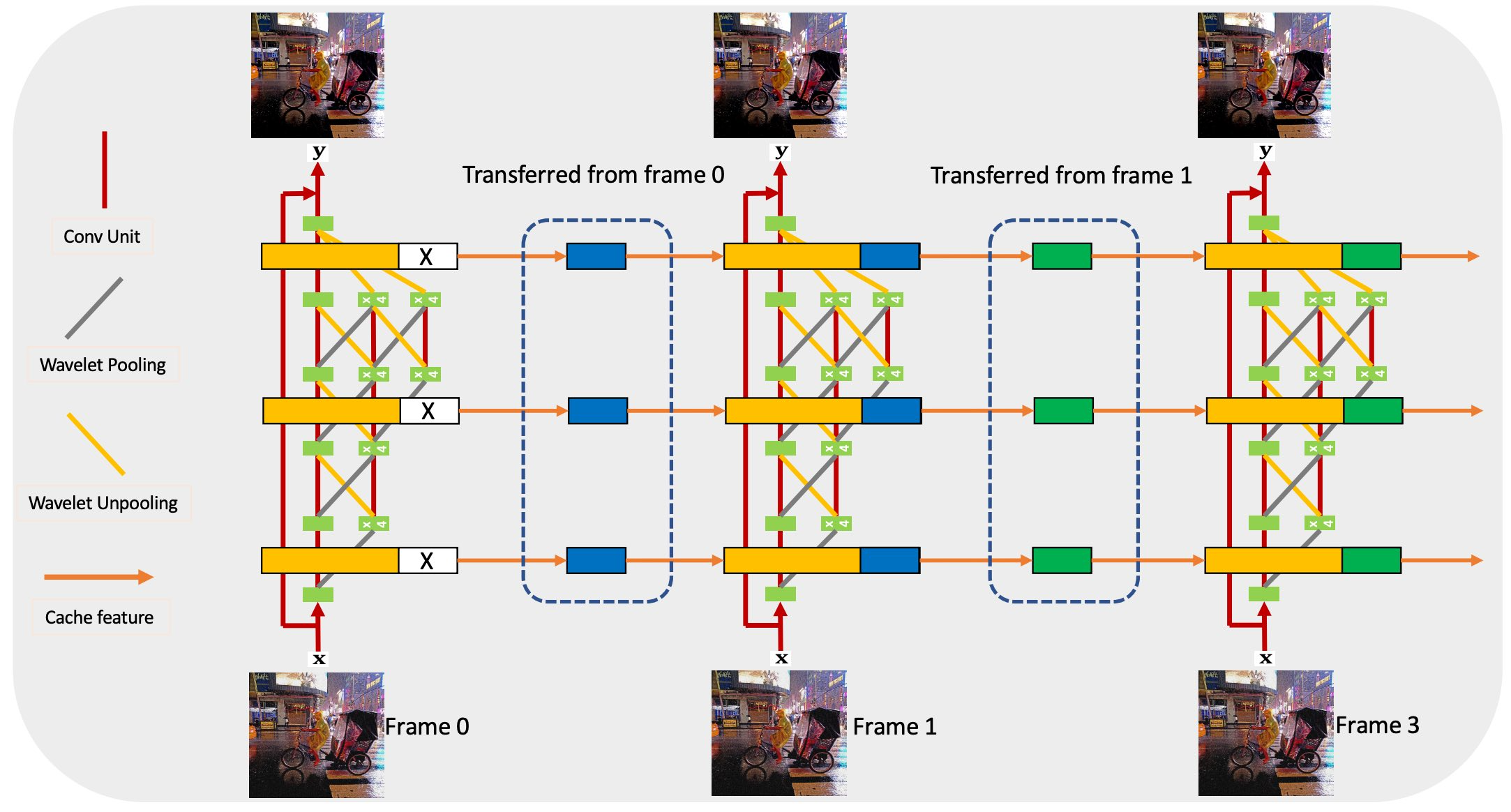
Proposed an end-to-end trainable burst denoising pipeline which jointly captures high-resolution and high-frequency deep features derived from wavelet transforms.
|

|
Extended our previous CVPR paper as an End-to-End pipeline from scene text detection and retrieval to
recognition.
|
|
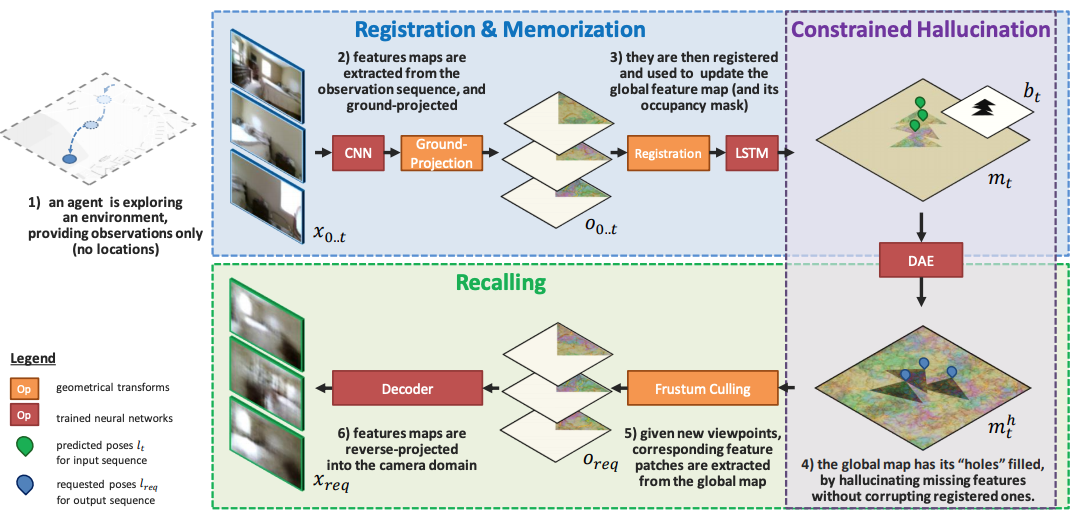
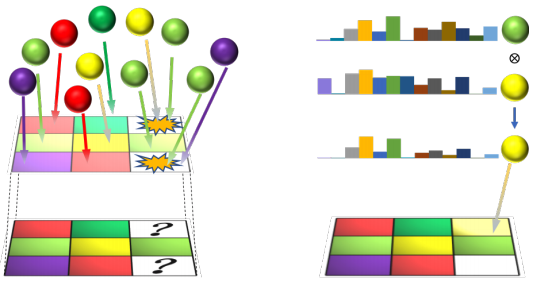
To incrementally generates complete and consistent 2D or 3D scenes with learned scene priors, while real observations of an actual scene can be incorporated, and unobserved parts of the scene can be hallucinated. Applications include autonomous agent exploration and few-shot learning. |
|
Presents a method of 3D point cloud segmentation using 2D supervision. A graph-based pyramid feature
network is proposed to capture global and local feature of points. A perspective rendering and semantic
fusion module is also introduced to offer refined 2D supervision.
|

|
Presents an effective end-to-end framework for detecting multi-lingual scene texts in arbitrary
orientations by integrating text attention model and global enhancement block with the pixel-link method
without adopting pretrained weights or extra synthetic datasets.
|

|
Combining the power of both instance-level scene text segmentation and visual phrase grounding.
|

|
To utilize text instances for understanding natural scenes, we have proposed a framework that combines image-based text localization with language-based context description for text instances. Specifically, we explore the task of unambiguous text localization and retrieval, to accurately localize a specific targeted text instance in a cluttered image given a natural language description that refers to it. |

|
We evaluate several of the most commonly used low-level features for real-world surveillance event
detection tasks.
|

|
Our system allows blind users to explore multi-floor environment with a wearable Tango device.
|
|
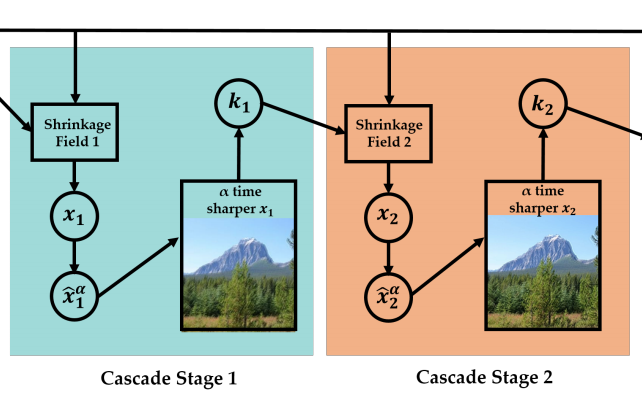
A framework is proposed to deconvolve blind image with patch-wise prior and adaptive shrinkage cascades.
|
|
We introduce an algorithm based on region trajectories to establish the connections between object localization in individual frames and video sequences. |

|
We presented a novel mobile wearable context-aware indoor maps and navigation system with obstacle
avoidance for the blind.
|

|
A wearable Obstacle Stereo Feedback (OSF) System for the Blind people based on 3D space obstacle
detection is presented to assist the navigation.
|
|
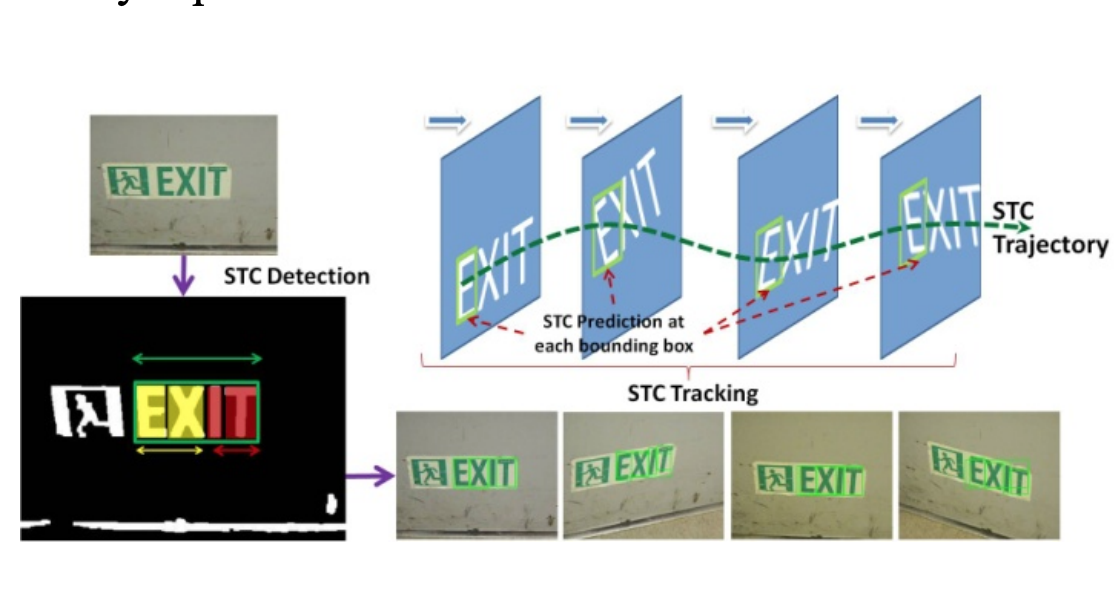
We proposed a multi-frame based scene text recognition method by tracking text regions in a video captured by a moving camera. Template from Jon Barron |